Indexing language
An indexing language is a "language1" used for subject classification or -indexing of documents. (Not used about systems for descriptive cataloging cataloging or -indexing).
Indexing languages may be divided into "classification systems" and "verbal indexing languages", although this is a superficial distinction. Lancaster (2003, p. 20-22) argues that one should not speak of assigning classification codes as "classification" as opposed to the assignment of indexing terms as "indexing". "These terminological distinctions are quite meaningless and only serve to cause confusion" (p. 21). That this distinction is superficial is also evident from the fact that a classification system may be transformed to a thesaurus and vice versa (cf., Riesthuis & Bliedung, 1991).
Classification systems may be divided into enumerative systems and faceted systems. Verbal indexing systems may be divided into "controlled vocabularies" and "free text systems". Controlled vocabularies may be divided into "pre-coordinative indexing systems" and "post-coordinative indexing systems". Descriptors (taken from thesauri), for example, represent "post-coordinative indexing systems".
Indexing languages are kinds of metadata. Their function is to serve as subject access points (or to supplement other kinds of subject access points, e.g. references, cf., citation Indexing)
Fig. 1: Traditional view of the kinds of indexing languages
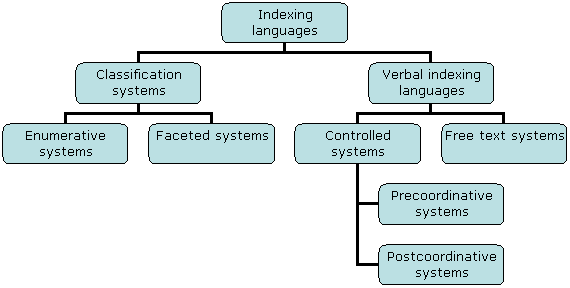
Fig. 2: Theoretically based view of the kinds of indexing languages
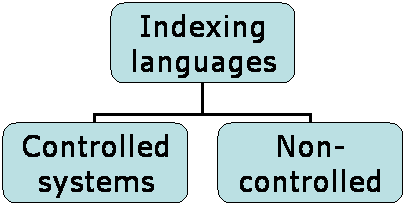
The most important property of an indexing language is whether the indexer has to assign a given unit to a pre-established conceptual system or not. If he has to assign to a pre-established system the most important property is whether the concepts or classes reflect the needs or not: Whether they have an adequate reflection of the subject to be indexed and whether the level of specificity is good. Only when these conditions have been met may other considerations be important. For example are hierarchical classifications more difficult to adopt to new developments compared with alphabetical systems.
Like other semantic tools are indexing languages systems of concepts with more or less information about semantic relations.
1Whether or not indexing languages should be considered languages in a linguistic sense is not to be discussed in this entry. Interested readers are referred to Hutchins, 1975.
Literature:
Barite, M. G. (2000). The notion of "category": Its implications in subject analysis and in the construction and evaluation of indexing languages. Knowledge Organization, 27(1-2), 4-10.
Fugmann, R. (2002). The complementarity of natural and index language in the field of information supply - An overview of their specific capabilities and limitations. Knowledge Organization, 29(3), 217-230. (Correction in Knowledge Organization, 2003, 30(1), 38-39).
Green, R. (1995). Syntagmatic relations in indexing languages: A reassessment. Library Quarterly, 65(4), 365-385.
Hutchins, W. J.
(1975). Languages of indexing and classification. A linguistic study of
structures and functions. London: Peter Peregrinus.
Maniez, J. (1997). Database merging and the compatibility of indexing languages. Knowledge Organization, 24(4), 213-224.
Lancaster, F. W. (2003). Indexing and abstracting in theory and practice. London: Facet Publishing.
Riesthuis, G. J. A. & Bliedung,St. (1991). Thesaurification of the UDC. In: Tools for Knowledge Organization and the Human Interface Vol. 2. Frankfurt: Index Verlag. (Pp .109-117).
Zhang, X. Y. (2006). Concept integration of document databases using different indexing languages. Information Processing & Management, 42(1), 121-135.
See also: IR-languages; Knowledge organization systems; Semantic tool
Birger Hjørland
Last edited: 19-10-2006